AI Performance Reviews
Performance reviews that people actually like.
Finally, performance management that runs itself. 90% faster reviews. 93% employee satisfaction. Zero nagging required.
First 10 users free, forever
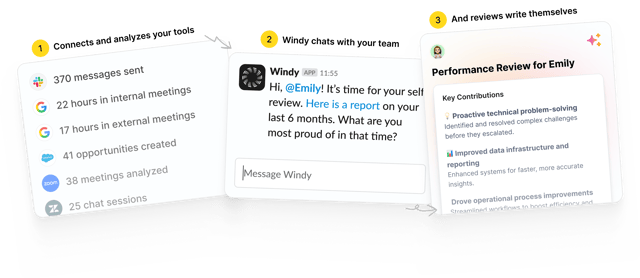









The work is already done. AI makes sense of it for you.
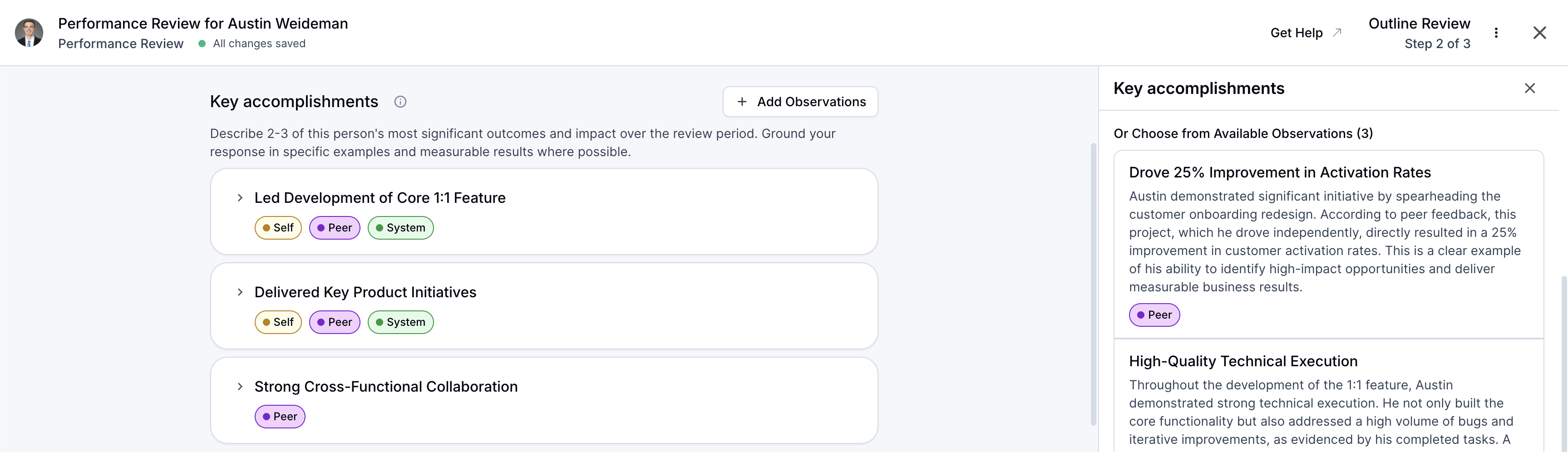
Performance Reviews
Performance reviews that run themselves.
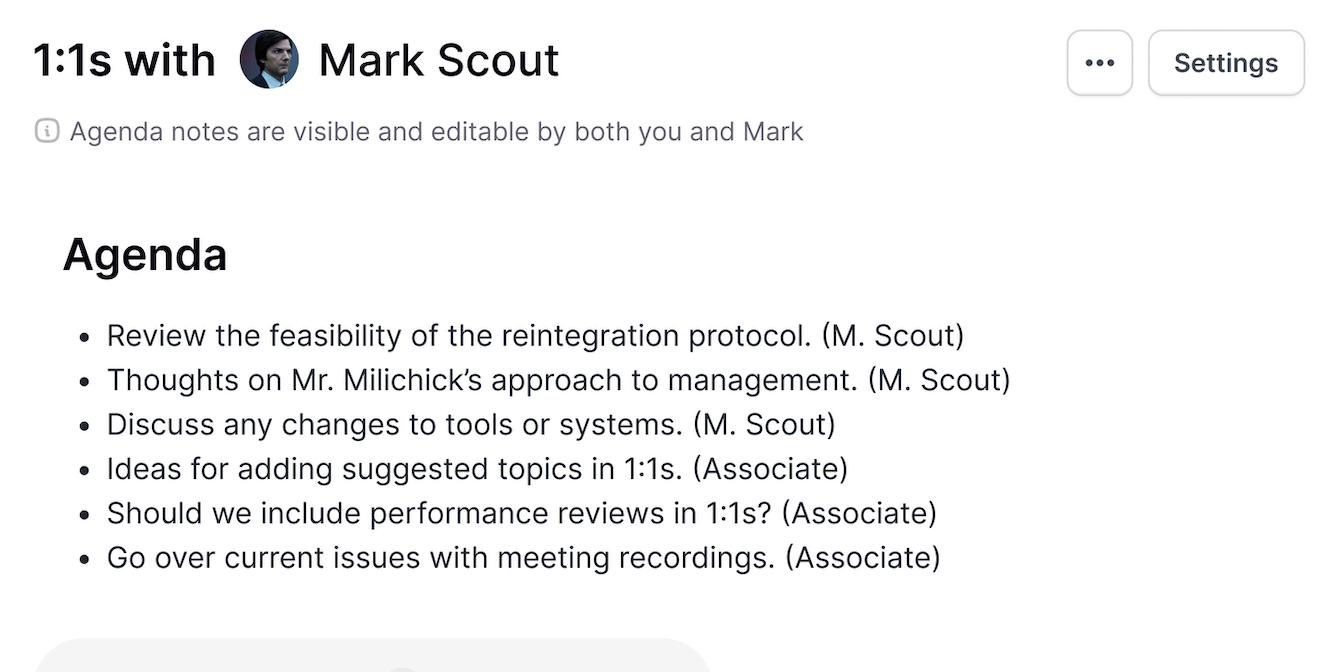
1:1s
Smart, automated agendas for effective 1:1 meetings with your team.
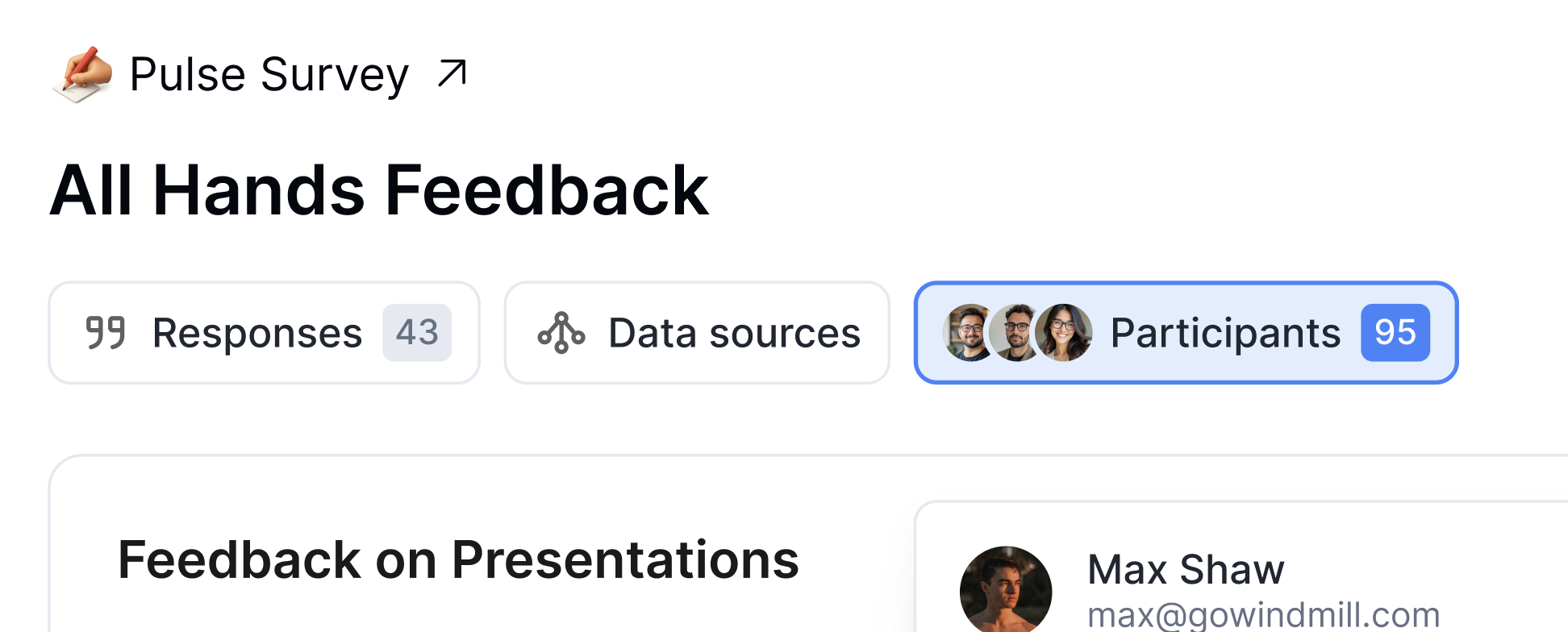
Pulse Surveys
Custom surveys to understand team sentiment, gather blockers, or run retros.
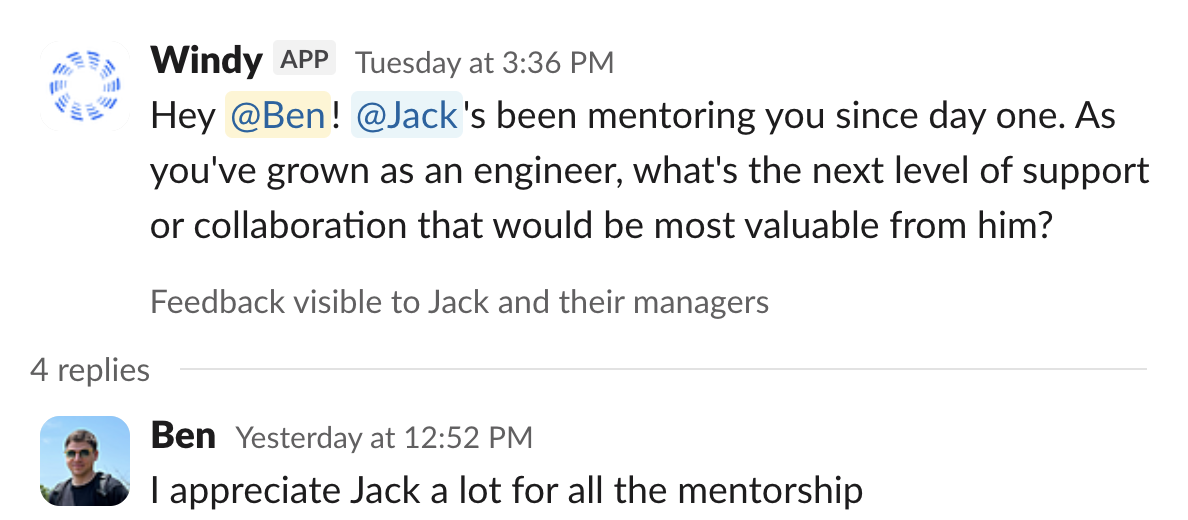
Continuous Feedback
Ongoing feedback system to help your team grow and improve consistently.
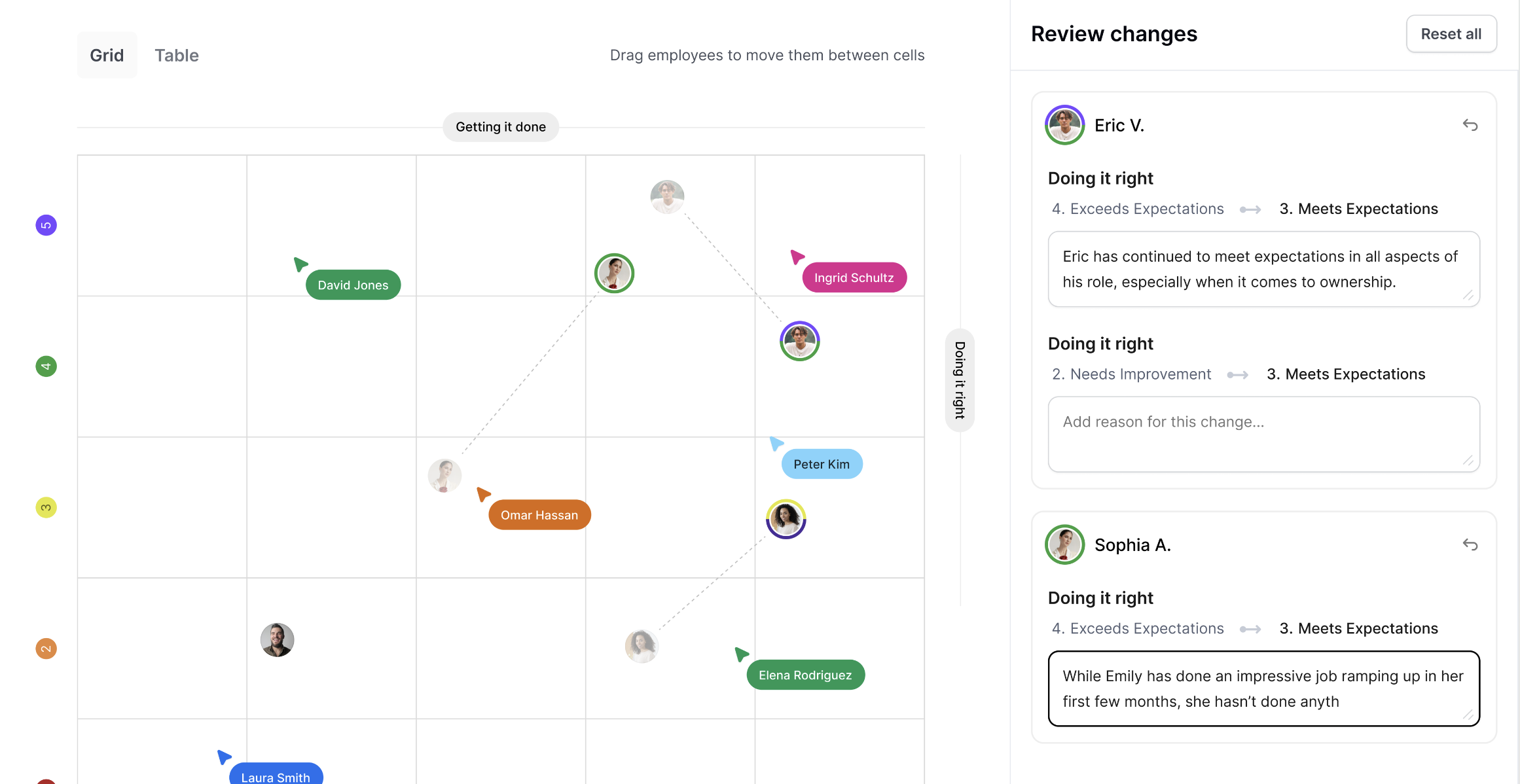
Calibrations
AI-powered pre-reads highlight discrepancies and flag biases for faster, fairer calibrations.
See how much time you're wasting.
Review Types
Enter your employee count to see potential savings
Real feedback from real users
Self-assessment was quick and easy compared to last year.
Windy feels like having a little assistant guiding the review process.
Easy, clear, and chatting in Slack sped things up.
Windy was extremely helpful recapping key moments.
Windy drafts were accurate—just needed slight tweaks.
Much smoother than 15Five.
Way better than previous review tools.
Layouts made reviews transparent and easy.
Instructions were clear and intuitive.
Review conversations felt natural and engaging.
A half a day's work can now be done in 30 minutes.
Record-speed without losing precision.
Windy made performance reviews painless.
I finished my review in minutes instead of hours.
The process was smoother and less time-consuming.
Summaries from Windy were spot on and useful.
Windy reminded me of accomplishments I'd forgotten.
Windy saved me half a day per review.
Windy is much better than 15Five—love it.
Best review experience I've had so far.
Review cycle was quick and efficient with Windy.
Windy helped me track achievements effortlessly.
Seamless and intuitive process.
The whole process felt lighter and more engaging.
Windy provided a great starting point for writing.
Windy turned a half-day task into 30 minutes.
Windy made feedback transparent and easy.
Backed by enterprise-grade security and scale
Security isn’t an add-on at Windmill. It’s integral to every layer of our system. We use industry-standard encryption and secure infrastructure to protect your data.
Still not sure if Windmill is right for you?
Let ChatGPT, Claude, or Perplexity do the research for you.
Click a button and see what your favorite AI says about Windmill.